SparkR 初探
R 大数据支持引擎的对⽐
R 的并行能力和对大数据的支持能力一直备受诟病,虽然 R 可以高效的进行数据 处理和机器学习任务,但 R 的处理能力受限于内存的大小。
现在 R 和分布式计算引擎的结合方案有如下四种:
RHadoop、RHipe、R + HadoopStreaming、SparkR
我们通过了解他们各自的优缺点可以为我们的选择作出一定的参考。
RHadoop 的优势: R 与 Hadoop 集成,为 R 处理大规模的数据提供了更好的 引擎。
RHadoop 的劣势: 需要了解 mapreduce 的思想、RHadoop 主要跟 Hadoop1.X 的结合较好。RHadoop 对于 Hadoop2.X Yarn 框架的设置资料奇缺。而且 R 语 言中的函数都要自己重新实现一遍。R+Hadoop 还不够成熟,企业级应用依然缺 乏成功案例。RHipe 的优势: 也是 R 和 Hadoop 的集成,为 R 处理大规模的数据提供了更 好的引擎。
RHipe 的劣势: 同 RHadoop 有类似的问题。R + HadoopStreaming 的优势: 通过用 R 脚本实现 Mapper 和 Reducer,通 过 HadoopStreaming 的方式调用 R 脚本实现的 Mapper 和 Reducer。个人认为这 种方式是 R + Hadoop 生产环境部署是最靠谱的一种。
SparkR 的优势: 与大数据全栈引擎 Spark 集成、R 与 Spark 的结合会极大 提升 Spark 在机器学习方面的优势地位,极大的简化使用者的学习成本,让我们 只关注所需要解决的问题本身。
SparkR 的劣势: Spark 和 R 的结合比较新,所以会存在稳定性和各种小问题。 但 Spark 社区活跃程度很高,在快速迭代的情况下各种小问题会很快解决。
通过对比各个R大数据支持引擎,最终我们选择了SparkR这个方案
SparkR 编译部署
CentOS 编译安装 R-3.2.2
1、下载
wget http://mirror.bjtu.edu.cn/cran/src/base/R-3/R-3.2.2.tar.gz
2、解压:
tar -zxvf R-3.2.2.tar.gz cd R-3.2.2.tar.gz
3、安装
yum install readline-devel
yum install libXt-devel
./configure
如果使用 rJava 需要加上 –enable-R-shlib ./configure –enable-R-shlib –prefix=/usr/R-3.2.2 make
make install
4、配置环境变量
vim ~/.bashrc
增加 PATH=/usr/R-3.2.2/bin :$PATH R_HOME=/user/R-3.2.2
5、测试
Rscript $R_HOME/lib64/R/share/R/tests-startup.R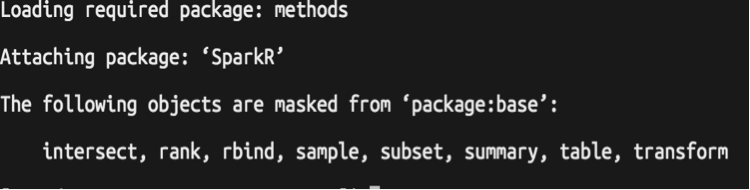
CentOS 下安装部署 Rstudio
1 、下载 Rstudio-Server
wget http://download2.rstudio.org/rstudio-server-rhel-0.99.483-x86_64.rpm
2、安装 Rstudio-Server
rpm –ivh rstudio-server-rhel-0.99.483-x86_64.rpm
3、创建 Rstudio-Server 的用户和用户组
groupadd rstudio_users
useradd rstudio_user
usermod -a -G rstudio_users rstudio_user
chown -R rstudio_user:rstudio_users /home/rstudio_user
4、配置 Rstudio-Server
cat “auth-required-user-group=rstudio_users” >>/etc/rstudio/rserver.conf
5、测试登陆
通过浏览器,我们访问 RStudio Server: http://172.16.190.28:8787/auth-sign-in
用户名和密码为 Linux 用户的用户名和密码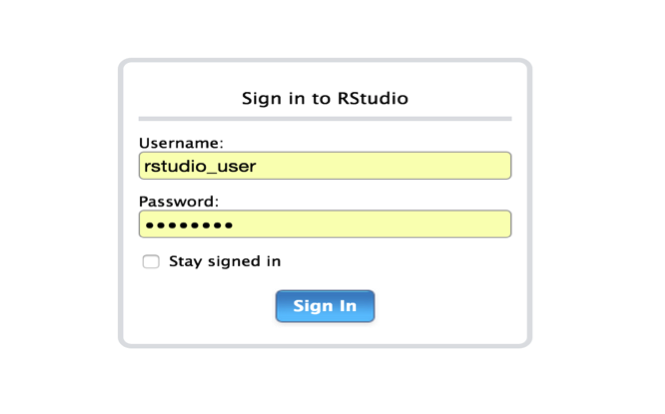
CentOS 安装部署 SparkR
下载 Spark 软件
git clone https://github.com/apache/spark
编译 SparkR
cd spark
git checkout branch-1.6.0
build/mvn -Phadoop-2.2 -Dhadoop.version=2.2.0 -Pyarn -Phive -Phive-thriftserver -Pspark-ganglia-lgpl -Psparkr -DskipTests clean package
发布
/make-distribution.sh -Phadoop-2.2 -Dhadoop.version=2.2.0 -Pyarn -Phive -Phive-thriftserver -Pspark-ganglia-lgpl -Psparkr -DskipTests clean package
部署 SparkR
mv dist spark-1.6.0
拷贝整个 spark-1.6.0 目录到部署的 Rstudio-Server 的机器上
修改~/.bashrc 指向 spark-1.6.0 的目录
在~/.Rprofile 的文件中增加
Sys.setenv(SPARK_HOME=”/home/rstudio_user/spark-1.6.0”)
.libPaths(c(file.path(Sys.getenv(“SPARK_HOME”), “R”, “lib”), .libPaths()))
测试 SparkR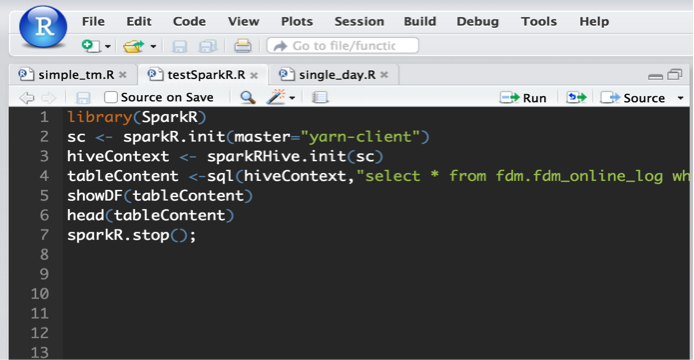
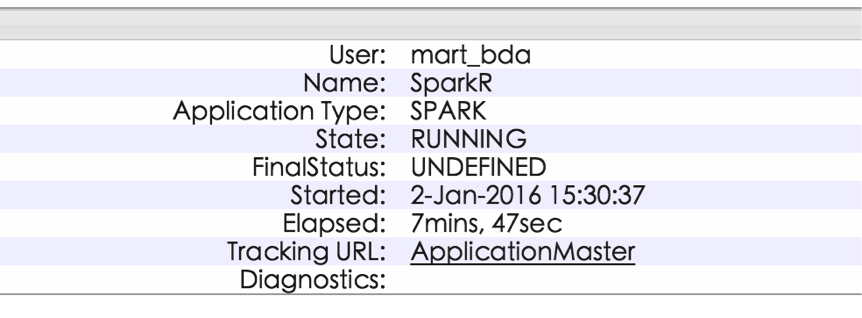
Have Fun in SparkR.
参考文档
Tessera Installation on Red Hat Enterprise Linux
RStudio Server 环境变量LD_LIBRARY_PATH的配置问题
Announcing SparkR: R on Apache Spark
Building Spark
R on Spark