Docker on Yarn 总体设计
背景介绍
数据挖掘平台通常需要用到各种繁杂的科学计算包,但所依赖的环境却不太相同。我们需要在集群中提供不同基础环境来运行这些科学算法包。
方案调研
我们可以在主机上安装不同版本的基础环境,然后用不同版本基础环境去处理各个科学计算包的依赖,但这样会导致主机上的环境混乱。例如多版本Python共存的问题就是典型的例子。
我们可以通过实现DockerContainer运行在Yarn框架上来实现每个任务的不同环境的定制。
Yarn对环境依赖复杂和隔离性需求高的应用程序支持不足,Docker的技术优势是提供任何程序能够运行在资源隔离的容器环境。
通过诸多的对比,Docker on Yarn 正是解决我们当前问题的最优的方案。
方案设计
为了解决背景介绍问题,为此我们进行了Docker on Yarn 的总体设计。
我们先来看一下Docker on Yarn 的整体流程图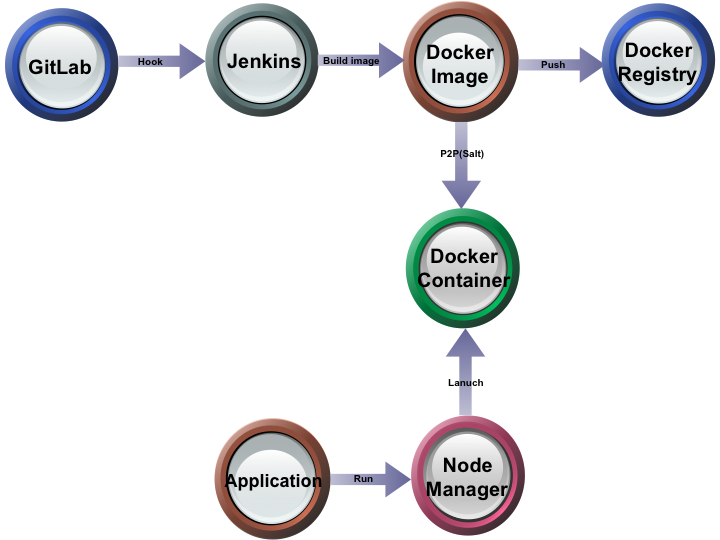
整体的流程大概如下:
- 在GitLab上存储各个集市的Dockerfile, 通过Merge事件触发Jenkins对Docker镜像的构建。
- 在Jenkins 来构建完Docker镜像之后,把镜像推到镜像仓库。
- 通过Jenkins把镜像save出来, 然后用Salt集群管理工具实现P2P的模式来大规模分发Docker镜像到集群节点供DockerContainer使用。
- 在客户端提交任务时指定运行DockerContainer和Docker的镜像,运行自己的Application。
- 提交的任务通过在NodeManager上用指定的Docker镜像初始化DockerContainer运行任务。
从整体的流程图中,我们可以看出Docker on Yarn 最关键的一步是实现DockerContianer的运行,
在下篇Docker on Yarn 的实践中,我们将讲述我们如何在基于Hadoop-2.7.1 源码实现DockerContainer。敬请期待
参考文档
Isolating YARN Applications in Docker Containers
Yarn-2644
Yarn-3611
Docker
Docker Blog